

postgresql应急手册骨干内容源自xiongcc的应急脑图,结合GPT深入研究得出结果。本人校核。
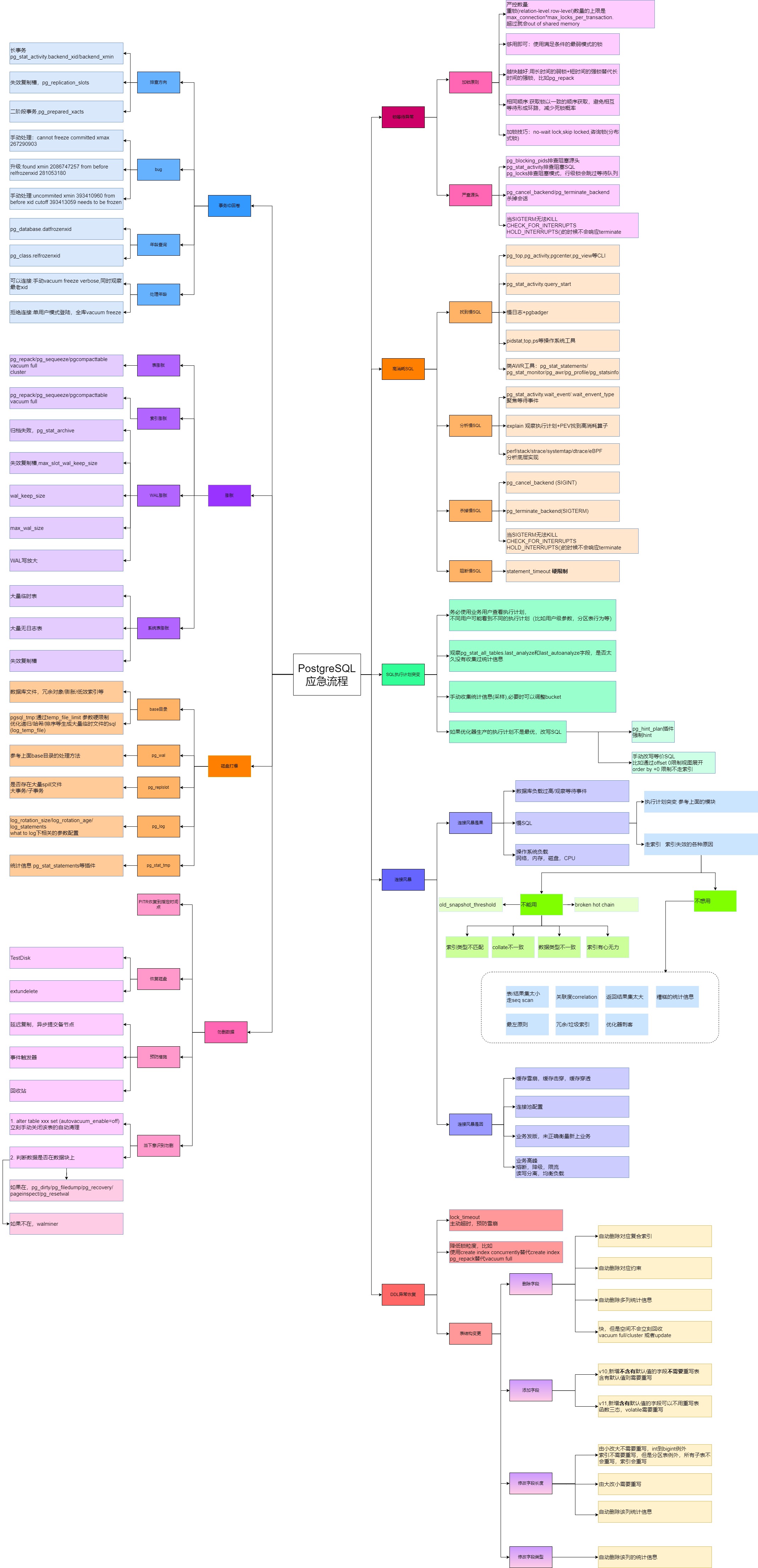
PostgreSQL 事务ID回卷异常及处理方案
1. 事务ID回卷异常的表现
概念说明: PostgreSQL使用32位事务ID(Transaction ID, XID)标识事务,每个新事务都会消耗一个XID (How to fix transaction wraparound in PostgreSQL? possible Txids))。由于32位整数最大约为42亿,XID会在约21亿(2^31)时触发“回卷”(wraparound)机制,从0重新计数。为了防止旧事务的数据可见性错误,PostgreSQL要求在接近XID耗尽时冻结(freeze)老事务ID。如果未及时冻结,数据库将采取保护措施,包括强制只读甚至停止服务,以避免数据丢失 (Overcoming VACUUM WRAPAROUND)。
日志警告: 当剩余事务ID不多时,PostgreSQL会连续发出警告倒计时。例如:
WARNING: database "mydb" must be vacuumed within 177009986 transactions
HINT: To avoid a database shutdown, execute a database-wide VACUUM in "mydb" ([PostgreSQL: Documentation: 8.2: Routine Vacuuming](https://www.postgresql.org/docs/8.2/routine-vacuuming.html#:~:text=WARNING%3A%20%20database%20,database%20VACUUM%20in%20%22mydb)).上述日志表示数据库“mydb”在约1.77亿个事务后将耗尽XID,需要尽快对整个数据库执行VACUUM以避免数据库关闭 (PostgreSQL: Documentation: 8.2: Routine Vacuuming)。此外,如果有极端长时间运行的事务阻碍了冻结,日志还可能出现诸如 WARNING: oldest xmin is far in the past 的提示,暗示存在过旧的打开事务需尽快结束 (How to fix transaction wraparound in PostgreSQL?)(“HINT: Close open transactions soon to avoid wraparound problems.”)。这种警告通常意味着某个长事务或未提交的准备事务正在阻止Autovacuum冻结老旧事务ID (突破事务 ID (TXID) 封装保护 | Cloud SQL for PostgreSQL | Google Cloud)。
错误及只读状态: 如果仍未采取行动,当距离XID极限不足约100万时,PostgreSQL会将受影响的数据库切换为只读模式,拒绝任何数据修改操作 (Overcoming VACUUM WRAPAROUND)。此时在该数据库上执行INSERT/UPDATE/CREATE等语句会报错。例如日志中可能出现:
ERROR: database is not accepting commands to avoid wraparound data loss in database "postgres"
HINT: Stop the postmaster and vacuum that database in single-user mode.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots. ([How to fix transaction wraparound in PostgreSQL?](https://www.postgresql.fastware.com/blog/how-to-fix-transaction-wraparound-in-postgresql#:~:text=drop%20stale%20replication%20slots.%202022,or%20drop%20stale%20replication%20slots))上述错误表示由于事务ID即将回卷,数据库“postgres”已进入保护模式,不再接受新的写入事务 (How to fix transaction wraparound in PostgreSQL?)。影响范围: 发生回卷风险的数据库将禁止写操作(只读),但仍可执行只读查询。在集群级别,由于所有数据库共享事务ID计数器,如果任何一个数据库达到回卷临界值,整个实例实际上都处于危险状态,需要立即处理。继续忽视将导致数据库崩溃停止,以强制管理员介入处理 (Overcoming VACUUM WRAPAROUND)。因此,事务ID回卷异常一旦出现,影响范围通常涵盖整个数据库实例,严重情况下会导致业务中断。
2. 接近事务ID回卷的检测方法
及时检测即将发生的XID回卷对于预防异常至关重要。DBA 可以通过系统视图和函数监控各数据库和表的事务ID使用情况:
数据库级检查: 查询
pg_database表的datfrozenxid冻结水位。使用age(datfrozenxid)函数可以查看距离每个数据库上次冻结点的事务数。 (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres AS oldest_current_xid))常用SQL示例如下:SELECT datname, age(datfrozenxid) AS xid_age, 2^31 - 1000000 - age(datfrozenxid) AS remaining FROM pg_database;上述查询结果显示每个数据库当前最大的事务ID年龄以及距离约2^31(回卷极限减去100万的安全裕度)还剩余的事务数 (突破事务 ID (TXID) 封装保护 | Cloud SQL for PostgreSQL | Google Cloud)。通常应关注
xid_age是否接近 2亿(默认autovacuum_freeze_max_age阈值)或更大。如果某个数据库的age(datfrozenxid)非常大(例如超过10^8量级),说明该数据库长时间未进行全库VACUUM,存在回卷隐患。表级检查: 即使数据库级别XID年龄正常,也可能有个别大表未及时清理而拖累全局。可以查询
pg_class的relfrozenxid来发现哪些表的冻结点最久远。例如:SELECT c.relname AS table_name, age(c.relfrozenxid) AS xid_age FROM pg_class c WHERE c.relkind = 'r' -- 普通表 ORDER BY xid_age DESC LIMIT 10;此查询列出事务ID年龄最大的若干表。若某表的
age(relfrozenxid)接近甚至超过autovacuum_freeze_max_age(默认2亿),则说明该表长时间未被VACUUM冻结,需尽快处理。特别要留意那些很少更新的大表,因为它们由于修改少,Autovacuum可能基于更新比例迟迟未运行,但其旧数据的XID仍在增长。同样地,带有TOAST数据的表应通过连接pg_class.reltoastrelid一并检查,以获取准确的老化程度 (How to fix transaction wraparound in PostgreSQL?)。Autovacuum状态: 通过监控
pg_stat_activity可以发现Autovacuum的防回卷行为。例如,当某个Autovacuum任务的查询字段显示 “(to prevent wraparound)” 时,表示它是高优先级的防事务ID回卷VACUUM (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres)。如果频繁看到这样的Autovacuum任务,或者日志中出现大量 “autovacuum canceled” 之类的信息,说明清理压力大、自动清理可能跟不上事务产生速度 (Overcoming VACUUM WRAPAROUND)。这也是需要调整策略的信号。
通过以上手段,DBA 可以提前发现事务ID使用已接近上限的数据库或表。在日常维护中,应将“XID年龄”作为一项重要监控指标,例如设置告警当某数据库的 age(datfrozenxid) 超过一定百分比(如50%或75%)的阈值 (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres)。一旦接近阈值,及时采取VACUUM措施,避免进入危险区域。
3. 事务ID回卷的预防措施
自动真空(Autovacuum)配置优化
开启并优化Autovacuum是防止XID回卷的首要措施。确保Autovacuum处于启用状态(autovacuum=on)且不会被人为关闭或过度限制。 (Overcoming VACUUM WRAPAROUND)实际生产中,以下参数可以调整以提升自动清理效率:
autovacuum_freeze_max_age: 默认值200百万事务。当表的事务ID年龄超过此值时,Autovacuum会触发一次紧急真空以冻结该表(即日志和pg_stat_activity中出现 “prevent wraparound” 的Autovacuum) (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres)。一般保持默认即可,确保系统有足够缓冲提前清理。不过对于极高事务吞吐的系统,可以考虑适当调高此值(例如提高到5亿或10亿),以减少过于频繁的冻结操作 (Managing Transaction ID Exhaustion (Wraparound)... | Crunchy Data Blog)。注意:调高后必须严格监控XID使用率,且确保有足够WAL存储空间(更大的XID跨度意味着pg_xact/pg_clog需要存储更多事务状态) (Managing Transaction ID Exhaustion (Wraparound)... | Crunchy Data Blog)。切勿将其设置接近21亿,以免Autovacuum来不及反应。autovacuum_vacuum_scale_factor: 控制Autovacuum根据表修改比例触发的阈值。对于非常大的表,默认0.2(20%变化)可能意味着需要几百万行更新后才清理。可针对大表将此值下调,例如0.05甚至更低,以更频繁地进行清理。配合autovacuum_vacuum_threshold(默认50行)一起调整,确保即使修改比例不高的巨表也能定期触发Autovacuum。autovacuum_naptime: 默认1分钟,表示Autovacuum调度周期。可视需要稍微降低以提高清理频率(例如30秒),尤其在高负载环境下让Autovacuum更及时地开始工作。Autovacuum并行度: 默认最多同时3个Autovacuum worker(
autovacuum_max_workers=3)。在有资源的前提下,可提高此值允许更多表并行清理,从而加快全库清理速度。注意每个Worker会消耗一定IO和CPU,需平衡系统负载。Autovacuum成本延迟: Autovacuum受真空成本限制参数控制(
vacuum_cost_delay默认20ms,vacuum_cost_limit默认200等),这些设置决定了Autovacuum的速度。默认设置较为保守。在高更新量导致清理滞后的情况下,可降低vacuum_cost_delay或提高vacuum_cost_limit,让Autovacuum更积极地工作,不至于因为过多让步而跟不上增长速度。针对特定表的Autovacuum设置: 可以通过
ALTER TABLE ... SET (autovacuum_vacuum_scale_factor=..., autovacuum_freeze_max_age=...)等为关键表定制参数。例如,对更新频繁的大表降低scale factor,对历史归档表降低freeze_max_age(甚至手动VACUUM FREEZE后提高阈值避免反复清理)。灵活的表级配置有助于在不影响全局的情况下优化特定表的清理策略。
总之,Autovacuum应作为防止XID回卷的第一道防线。绝大多数回卷问题源于Autovacuum未能正常运行(被关闭、配置不当或频繁被阻塞) (Overcoming VACUUM WRAPAROUND)。通过合理调整以上参数,让自动真空既“勤快”又不过度干扰业务,可以大幅降低出现事务ID回卷风险的概率。
手动 VACUUM 使用建议
即使有Autovacuum,某些场景下仍需要DBA主动介入执行手动VACUUM来预防问题:
定期全库真空: 正如官方建议,最好定期对整个数据库执行VACUUM。例如可在业务低峰每日或每周运行一次
vacuumdb --all --freeze --jobs=N(带分析则加--analyze)对所有数据库进行清理 (PostgreSQL: Documentation: 8.2: Routine Vacuuming)。这样可以冻结大量旧事务ID,并更新统计信息。一些高负载系统甚至每隔几分钟就手动清理热点表 (PostgreSQL: Documentation: 8.2: Routine Vacuuming)。定期的手动全库VACUUM能作为Autovacuum的有力补充,防止因某些原因Autovacuum遗漏清理而积累风险。关注长时间无更新的表: 那些历史归档表或长期只读表,由于很少更新,Autovacuum可能极少触发。但它们的数据XID随着时间推移变老,同样需要冻结。一种策略是在这些表加载完数据后手动执行
VACUUM FREEZE。这会将全表的事务ID冻结为“FrozenXID”,后续即使XID回卷,这些数据也保持可见。冻结后的表Autovacuum会将其页面标记为“all frozen”,以后Vacuum可跳过这些页面 (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres)。这不仅降低回卷风险,也减少未来清理IO开销(PostgreSQL 9.6+可跳过已冻结的页面,PG11+对索引也有类似优化) (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres)。因此,对老旧静态数据执行一次手动冻结有长远益处。监控并处理Autovacuum瓶颈: 如果发现Autovacuum经常因锁冲突被取消(日志出现大量“canceling autovacuum task”)、或有长事务长期占用导致无法清理(日志警告oldest xmin),DBA应考虑在适当时机暂停相关应用写入,手动执行VACUUM。例如,结束阻碍清理的长事务后,立即对受影响的表运行VACUUM。同时,尽量避免长事务和未提交的批量操作长时间占用,以减少对清理的干扰。
VACUUM FULL 谨慎使用: 在空间回收需求很大时,可考虑
VACUUM FULL。它会重写表并回收空间,同时也隐含冻结效果。但由于会长时间锁表,生产中应慎用 (PostgreSQL: Documentation: 8.2: Routine Vacuuming) (PostgreSQL: Documentation: 8.2: Routine Vacuuming)。对于回卷预防而言,普通的 VACUUM FREEZE 已足够且开销更低;只有在明确需要回收大量空间时才使用VACUUM FULL。
总结: 手动VACUUM是Autovacuum机制的补充。DBA应制定合适的VACUUM策略,包括定期维护和在关键阈值前的人工干预,确保不会因为等待自动清理而错过最佳时机。特别是在大量数据导入、批量删除之后,以及重大业务操作完成后,执行一次VACUUM可以重置事务ID年龄,清除隐患。
参数设置建议
除了Autovacuum相关参数,以下与冻结和回卷相关的参数也值得关注:
vacuum_freeze_min_age: 默认50百万。表示VACUUM在扫描表时,将冻结那些超过此年龄的事务ID的行。 (6.3. Freeze Processing - Hironobu SUZUKI @ InterDB)适当降低此值可以使每次VACUUM更积极地冻结较新的行,从而减缓事务ID老化速度。不过过低会导致频繁冻结增加开销,一般保持默认即可。除非遇到特定表更新模式导致Autovacuum总是错过冻结窗口,可考虑调小此值让普通VACUUM更多冻结。vacuum_freeze_table_age: 默认150百万。表示当表的年龄超过此值时,即使是普通VACUUM也会被强制转换为“aggressive vacuum”来冻结较新的行。这与autovacuum_freeze_max_age共同配合,确保在达到硬上限之前多个阶段就开始冻结。通常不需要调整此参数。autovacuum_multixact_freeze_max_age等多事务ID相关参数: 如果应用大量使用共享锁(例如外键或SELECT FOR SHARE导致MultiXact ID增长),也需关注多事务ID的冻结。多事务ID(MultiXact ID)有独立的Wraparound限制和参数控制(默认值类似于XID) (PostgreSQL: pgsql: Add wraparound failsafe to VACUUM.)。在旧版本(例如9.3~9.5)曾发生过MultiXact wraparound问题,务必升级到最新补丁版本并确保Autovacuum同时冻结MultiXact。新版本中引入了类似failsafe机制避免MultiXact耗尽 (PostgreSQL: pgsql: Add wraparound failsafe to VACUUM.)。如果系统涉及大量多事务ID操作,建议适当调低vacuum_multixact_freeze_min_age及监控相关视图(如pg_stat_all_tables中的relminmxid年龄)。其他注意: 切勿将
autovacuum关闭或长期禁用某些表的Autovacuum。这种做法极易导致事务ID耗尽而措手不及 (Overcoming VACUUM WRAPAROUND)。如果因性能考虑临时关闭Autovacuum,一定要有配套的手动VACUUM计划。对于迁移或备份恢复后大量数据导入的库,完毕后应尽快运行VACUUM以冻结XID。最后,确保track_counts=on(默认开启)以使Autovacuum能正常跟踪表的修改统计,否则Autovacuum可能无法按预期触发。
通过合理的参数设置,DBA 可以平衡系统性能与清理频率,在不影响正常业务的情况下预防XID回卷。
4. 应对事务ID回卷风险的应急处理
即使做好了预防,有时仍可能遇到事务ID回卷的紧急情况(例如忽视警告导致数据库进入只读)。以下是生产环境中的应急处理方案:
阶段1:在线强制VACUUM降龄
如果从日志警告发现回卷风险且数据库尚未进入只读(还能执行写操作),应立即采取行动:
全库冻结VACUUM: 以超级用户运行对该数据库的VACUUM命令。例如:
VACUUM FREEZE;(会冻结当前数据库所有表的老旧事务ID)或使用命令行工具vacuumdb -U postgres --freeze --dbname=<数据库名>对目标库执行冻结真空。 (How to fix transaction wraparound in PostgreSQL?)这会显著降低age(datfrozenxid),解除回卷威胁。注意:如果数据库规模很大,此操作可能耗时较长,最好在维护时段执行,并监控进度。逐库检查处理: 如果一个实例中多个数据库XID均接近上限,需要对每个数据库分别执行VACUUM。在前述命令基础上加上
--all参数可以一次性遍历所有数据库:vacuumdb -U postgres --freeze --all。这样可以确保整个实例安全。完成后通过前述检测查询核实age(datfrozenxid)已大幅下降。处理阻碍因素: 在执行VACUUM过程中,留意是否有长事务、未提交的预备事务或复制槽阻碍清理。如果VACUUM无法快速完成,可检查:
使用
SELECT * FROM pg_stat_activity WHERE state <> 'idle';找出长时间运行的事务,考虑终止(pg_terminate_backend)掉非常长久且无关紧要的事务,以解除对冻结的阻挡。查询
pg_prepared_xacts,如果有非常老的已准备事务 (prepared transactions),应尽快在事务管理器层面 COMMIT 或 ROLLBACK 之,否则它们的存在会使Oldest XID无法前移。查询
pg_replication_slots,如果有复制槽的catalog_xmin非常小(表示保留了很久的事务ID),且对应的从库已不再需要或滞后严重,可考虑暂时移除该复制槽(SELECT pg_drop_replication_slot('slot_name');)以释放XID冻结的限制 (How to fix transaction wraparound in PostgreSQL?)。这些措施应在评估业务影响后进行。
通过上述步骤,通常可以在不停止服务的情况下解除回卷风险。然而,如果数据库已经进入只读模式(出现“database is not accepting commands...”错误)且无法执行VACUUM,则需进入下一个阶段。
阶段2:单用户模式下处理
当数据库因为回卷保护已拒绝写入时,只能通过服务器维护模式进行处理。具体步骤如下:
停止数据库服务: 通知业务停机并执行
pg_ctl stop -m fast等命令停止PostgreSQL服务。确保进程已完全退出。以单用户模式启动: 使用PostgreSQL的单用户模式启动目标数据库实例。命令示例:
postgres --single -D <数据目录> -c config_file=<配置文件路径> <数据库名>这将在控制台直接进入指定数据库的单用户命令提示符。在单用户模式下,没有多用户调度和锁管理,适合紧急维护操作。 (How to fix transaction wraparound in PostgreSQL?)
执行冻结VACUUM: 在单用户提示符下,对数据库执行冻结操作:
VACUUM FREEZE;由于此时只能连接当前数据库,该命令会遍历该库的所有表进行真空冻结。如果有多个数据库都超限,需要对每个数据库分别重复此过程(逐个指定数据库名启动单用户模式并执行VACUUM)。如果单用户模式下VACUUM出现错误(例如遇到临时表无法访问等),可以尝试改用
VACUUM FULL逐表处理。不过通常VACUUM FREEZE足以解决XID问题且更快。重启服务: 单用户VACUUM成功完成后,退出(single-user模式通过按EOF/Ctrl+D或输入
\q),再正常启动PostgreSQL(pg_ctl start)。此时数据库应恢复为可读写状态。务必再次运行检测命令确认age(datfrozenxid)已恢复到安全范围。后续措施: 立即检查并处理导致此次问题的根源。例如,如果因为Autovacuum被停用了,立刻开启;如果因为长事务未管理,则完善监控和限制。还应检查是否有
template0这类数据库因为默认不允许连接而长期未冻结(一般初始化时已冻结,无特别问题)。另外,对于此前提到的预备事务和复制槽,如果未处理,在服务重启后仍需处理(因为单用户模式可能无法处置这些跨会话对象)。确保环境中无类似隐患后,才能恢复正常业务运行。
注意:单用户模式操作具有破坏性,一定要确保已停止所有应用连接并备份关键数据。单用户VACUUM时若发生异常退出,可能需要借助更低级手段(如pg_resetwal)才能恢复,此种情况极为少见但需谨慎对待。
阶段3:备份与还原(最后手段)
如果由于某种原因,VACUUM无法在可接受时间内完成(例如数据量极其庞大导致单用户VACUUM耗时过久,业务无法长时间停机),或者VACUUM遇到无法绕过的错误,可以考虑逻辑备份/还原方式解决:
只读导出数据: 在数据库处于只读模式下,尽管无法写入,但仍可执行SELECT。这时可以使用
pg_dump对数据库进行完全导出(也可以pg_dumpall导出整个实例)。由于数据仍然完整可读,这种方式不会丢失数据。但要注意导出过程本身可能很耗时,要评估其可行性。初始化新实例: 在另一个服务器或本机不同数据目录,初始化与原版本相同的新PostgreSQL实例(
initdb)。确保配置与原实例兼容(字符集、locale等)。导入恢复: 将前一步导出的SQL或压缩文件导入新实例(使用
psql或pg_restore)。新的实例中所有数据将被赋予全新的事务ID(从头开始计数),不会存在历史XID的问题。注意:导入时要有足够空间,因为这是逻辑重建过程。切换业务连接: 验证新实例数据正确且完整后,将应用切换到新实例。此过程中需要较长停机窗口,但切换完成后,事务ID回卷问题即彻底消除。
备份旧实例: 在销毁旧实例前,可保留其数据文件备份以防万一。但通常如果新实例运转正常,旧实例可以下线。
逻辑备份恢复是最后的手段,在其他方法无法奏效时才实施。它的优点是彻底重置XID计数,但缺点是需要长时间停机和大量IO。在生产环境中,应尽可能通过及时VACUUM避免走到这一步。
特别提醒:某些资料提及的
pg_resetxlog(PostgreSQL 12起改名为pg_resetwal)工具也能强制重置事务ID计数器。然而这会跳过正常的冻结步骤,可能导致未提交事务的数据不一致 (How to fix transaction wraparound in PostgreSQL?)。不建议在有其他选项时使用此工具。只有在数据库已无法启动且无备份可用的极端情况下,才考虑使用pg_resetwal,并必须在重启后立即执行全库VACUUM以弥补冻结。相较之下,逻辑备份/还原更安全可控。
5. 不同PostgreSQL版本的注意事项
事务ID回卷机制在各版本基本原理相同,但性能优化和默认设置有所不同:
PostgreSQL 9.x 版本: 早期9.0-9.4版本的Autovacuum相对不完善,一些版本曾出现过多事务ID冻结的BUG(特别是9.3引入多事务ID后,需升级补丁避免multixact wraparound问题)。在9.6之前,VACUUM 冻结无法跳过已冻结的页面,每次反_wraparound的VACUUM都必须扫描整个表,导致大表冻结开销很高 (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres)。因此在9.x版本,DBA需要更加勤勉地手动VACUUM长久未变的表,并密切监控XID年龄。此外,默认参数在老版本可能偏保守,例如默认
vacuum_cost_delay较高,在高负载场景下需要手动调低以防止清理滞后。PostgreSQL 9.6 的改进: 9.6引入了可见性映射(Visibility Map)的冻结标记机制。VACUUM在冻结了整页所有元组后,会将该页标记为“All-Frozen”,下次非Aggressive VACUUM可直接跳过这些页 (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres)。这意味着只要对大表进行过一次全面冻结,后续的维护成本大幅降低。同样,9.6开始Autovacuum对防回卷VACUUM的策略也更智能:即使关闭Autovacuum,PostgreSQL内核仍会在需要时强制启动防回卷的autovacuum进程(以避免致命问题)。因此运行9.6及以上版本,相对于9.4/9.5,发生意外wraparound的概率降低,但仍需要正确配置Autovacuum。
PostgreSQL 11 的改进: PG11在索引清理方面进行了优化,使冻结时对索引的处理开销减少 (PostgreSQL 教程: 检查事务 ID 耗尽 - Redrock Postgres)。因为冻结只影响Heap表的数据可见性标记,不会修改索引,PostgreSQL 11能够在某些情况下跳过不必要的索引扫描,从而加速VACUUM。另外PG11还提升了并发性能,使长时间冻结操作对前台负载影响更小。
PostgreSQL 13+ 版本: PostgreSQL 13 引入了并行 VACUUM,对大型表的清理可以利用多CPU并行处理索引,从而加快完成VACUUM的时间。这对防止wraparound的长时间VACUUM特别有利,能在更短时间内冻结大量页。在13之前,VACUUM索引是单线程的,大表可能清理非常久。
PostgreSQL 14 的改进: PG14加入了事务ID回卷保护的应急机制(Failsafe) (PostgreSQL: pgsql: Add wraparound failsafe to VACUUM.) (PostgreSQL: pgsql: Add wraparound failsafe to VACUUM.)。当Autovacuum检测到某表的
relfrozenxid已经非常接近危险值(默认阈值1.6 billion,由新参数vacuum_failsafe_age控制)时,会自动触发Failsafe模式。在该模式下,VACUUM会采取非常措施:取消所有成本延迟、跳过剩余的索引清理和非必要的页清理,专注于尽快完成剩余的冻结操作 (PostgreSQL: pgsql: Add wraparound failsafe to VACUUM.)。这一机制确保在逼近极限时VACUUM能够以最快速度推进。而在PG14之前,若VACUUM由于成本限制运行缓慢,管理员可能需要手动调参数甚至停止应用来加速清理。现在PG14+会自动解除“刹车”以避免灾难。此外,PG14默认提供vacuum_failsafe_age=1600000000(1.6B) 和对应的vacuum_multixact_failsafe_age,作为额外保险。 (PostgreSQL: pgsql: Add wraparound failsafe to VACUUM.) (PostgreSQL: Documentation: 17: VACUUM)文档也指出,一旦触发failsafe,VACUUM将绕过索引清理等以避免wraparound,通常不需要手动干预 (PostgreSQL: Documentation: 17: VACUUM)。其他版本差异: 新版本在日志和监控方面也更加友好。例如PG10+的日志会明确提示哪个表启动了“anti-wraparound VACUUM”。PG12起取消了
txid旧事务ID对某些系统表单独处理的过时逻辑,统一由Autovacuum管理所有表的冻结。总的来说,随着版本升级,PostgreSQL在防止事务ID回卷方面变得更高效和安全。DBA 应充分利用新版本特性,及时升级老旧版本(尤其9.x已属非常陈旧,存在性能和安全隐患)。
总结建议: 无论哪个版本,保持良好的维护习惯是关键——持续监控XID使用、适当配置Autovacuum、及时处理长事务和清理死版数据。对于仍在使用老版本的企业,应计划升级到更新的受支持版本,以利用改进的VACUUM机制和回卷防护特性。这样才能最大限度地降低生产环境中遇到事务ID回卷异常的几率,保证数据库持续稳定运行。 (Overcoming VACUUM WRAPAROUND) (Overcoming VACUUM WRAPAROUND)